 Photo by rawpixel on Unsplash
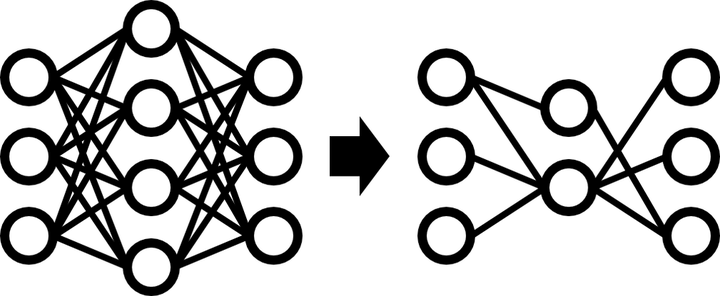
Photo by rawpixel on UnsplashImage compression is crucial as images continue to increase in number due to advancements in computing power and mobile camera capabilities. To save space and transfer images more quickly, it is necessary to reduce the size of digital images while maintaining their necessary information. Deep Neural Networks (DNNs) have become powerful tools for various computer vision tasks, including image compression. However, DNNs are computationally intensive, requiring acceleration techniques to meet increasing needs. These techniques can be categorized into three categories: memory compression, computational optimization, and dataflow optimization. Model compression falls under the category of memory compression and the goal is to achieve a model that is simplified from the original without significantly diminishing accuracy and with a reduction in size and/or latency from the original. This project focuses on model compression techniques, such as pruning and quantization, on image compression algorithms to compare the performance of the compressed models to the original models. Our results show that pruning has different effects when applying to different components of the image compression models.
Jennifer Yu
MSc. Student
My research interests include distributed robotics, mobile computing and programmable matter.