Automated Clinical Note Generation from Doctor-Patient Conversations using Large Language Models
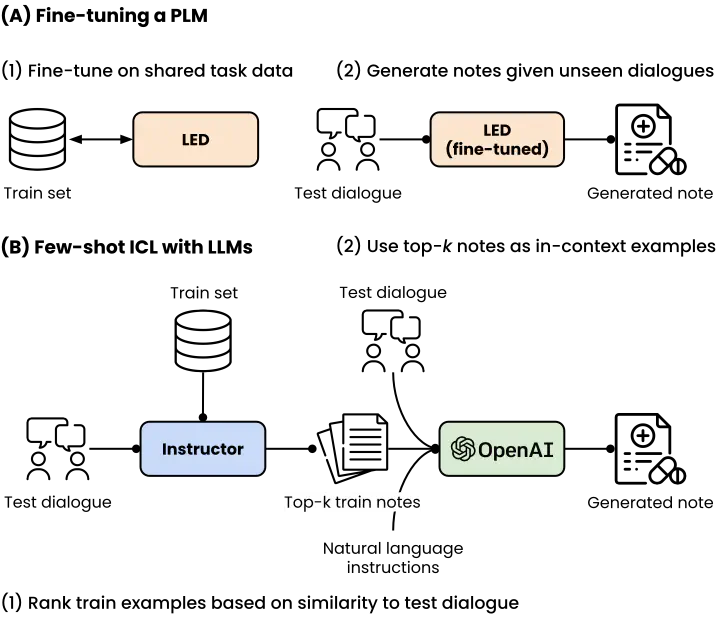 Photo by rawpixel on Unsplash
Photo by rawpixel on UnsplashIn this paper, we introduce advanced solutions to the 2023 MEDIQA-Chat challenge, focusing on the automated generation of clinical notes from physician-patient dialogues. Our models achieved first place in both Task A and Task B, which involved generating individual note excerpts and complete notes, respectively. We employed state-of-the-art large-language-model (LLM) based approaches, including fine-tuning FLAN-T5-Large, Longformer Encoder-Decoder (LED), and In-Context Learning (ICL) with GPT-4, and explored zero-shot/few-shot learning and prompt engineering techniques to enhance our solutions. In Task A, our fine-tuned FLAN-T5-Large model demonstrated competitive performance, achieving a header accuracy of 0.78, Rouge1 score of 0.4466, Rouge2 score of 0.2282, Bertscore F1 score of 0.7303, Bleurt score of 0.5593, and an aggregate score of 0.5789, outperforming the second and third place teams with aggregate scores of 0.5739 and 0.5622, respectively, achieving first place among 31 entries. In Task B, both our GPT-4+ICL approach and the fine-tuned LED approach consistently ranked higher than all other 19 entries in the MEDIQA-Chat2023 competition, with our GPT-4+ICL approach achieving the highest aggregate scores across all sections, and an average section score of 0.6483. These results demonstrate the potential of our methods in contributing to the development of automated tools that assist healthcare professionals in generating accurate clinical notes and enhancing patient engagement. The findings of this study hold implications for the future of natural language processing and machine learning applications in the healthcare domain, and indicate the promise of large-language-models in improving the documentation and communication of patient information by medical professionals.
Jennifer Yu
MSc. Student
My research interests include distributed robotics, mobile computing and programmable matter.